from searchtweets import load_credentials, ResultStream, gen_request_parameters, collect_results
search_args = load_credentials(filename="search_tweets_creds.yml",
yaml_key="search_tweets_api",
env_overwrite=False)
empresas = ["Telecentro", "MovistarArg", "ClaroArgentina", "PersonalAr"]
empresas_tweets = dict()
for empresa in empresas:
query = gen_request_parameters(empresa, results_per_call=100, granularity=None)
tweets = collect_results(query,
max_tweets=100,
result_stream_args=search_args)
empresas_tweets[empresa] = tweets[0]['data']El Procesamiento de Lenguaje Natural o PLN es el campo de estudio sobre el análisis computacional del lenguaje humano. Esta área de conomiento incluye una variedad muy amplia de técnicas y aplicaciones. Una de ellas, dentro del ámbito del análisis y comprensión del lenguaje, es el Análisis de Sentimientos, una aplicación que permite clasificar un texto de acuerdo a su carga o polaridad positiva, negativa o neutra.
Aquí veremos como con unas pocas líneas de código python uno puede:
- Conectarse a la API de Twitter
- Descargar los últimos twitts en los que se menciona a determinadas empresas TIC
- Utilizar un modelo de machine learning pre-entrenado para realizar el análisis de sentimientos de los twitts
- Visualizar el análisis
El modelo pre-entrenado que vamos a utilizar es RoBERTuito, un modelo entrenado con 500 millones de tweets en Español. Los autores del paper/modelo lo disponibilizaron en forma gratuita a través de la plataforma HuggingFace y librería pysentimiento para facilitar la investigación y las aplicaciones de PLN en Español.
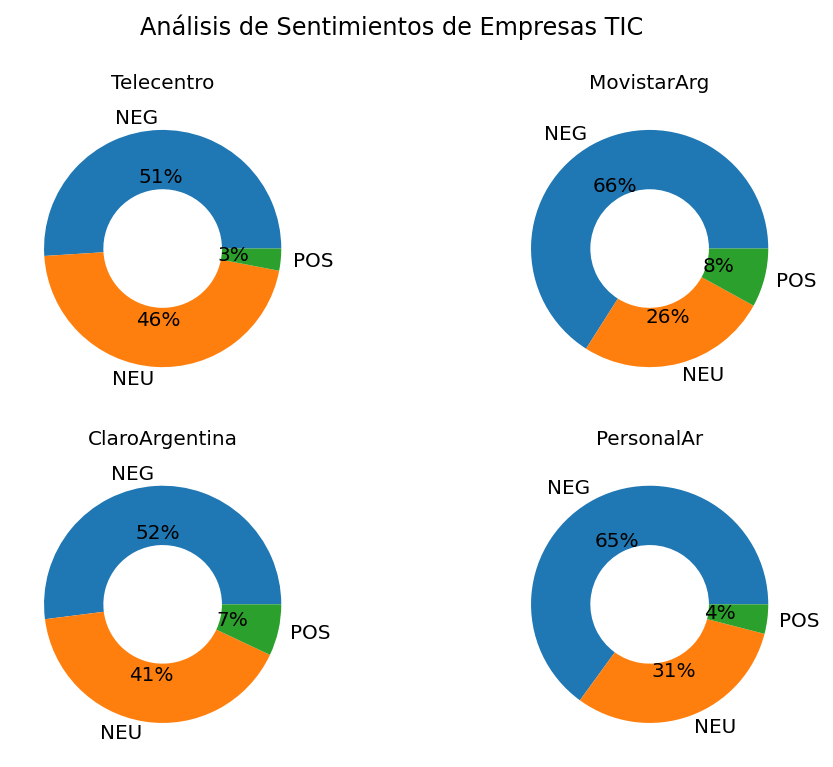
Aclaración 1: es natural y esperable que las menciones a las empresas en redes tengan un sesgo negativo, ya que es uno de los canales para hacer llegar reclamos y por tratarse de un servicio pago no es habitual que la conformidad con el servicio redunde en menciones positivas.
Aclaración 2: para acceder a los tweets con las menciones es necesario primero tramitar credenciales de autenticación en Twitter for Developers. Las mismas estarán guardadas en un archivo llamado search_tweets_creds.yml con la siguiente forma:
search_tweets_api:
bearer_token: MY_BEARER_TOKEN
endpoint: https://api.twitter.com/2/tweets/search/recentPara adquirir los tweets utilizaré la librería searchtweets-v2, un Cliente de Python para la Versión 2 de la API de Twitter.
Con el siguiente código me autentico y requiero los últimos 100 tweets que mencionan a cada una de las empresas que nos interesan:
Preproceso los tweets, aplico el análisis de sentimientos y extraigo la categoría para cada uno de los tweets y empresas:
from pysentimiento import create_analyzer
analyzer = create_analyzer(task="sentiment", lang="es", model_name="pysentimiento/robertuito-sentiment-analysis")
empresas_tweets_sent = dict()
empresas_tweets_sent_out = dict()
for empresa in empresas:
empresas_tweets_sent[empresa] = [analyzer.predict(tuit) for tuit in empresas_tweets_proc[empresa]]
empresas_tweets_sent_out[empresa] = [tuit.output for tuit in empresas_tweets_sent[empresa]]Visualizo los resultados:
import numpy as np
import matplotlib.pyplot as plt
empresas_tweets_sent_count = dict()
fig, axes = plt.subplots(2, 2, figsize=(8, 6),dpi=144)
plt.suptitle("Análisis de Sentimientos de Empresas TIC")
array_index = [(0,0), (0,1), (1,0), (1,1)]
axes_title_font_size = 10
for empresa, index in zip(empresas, array_index):
empresas_tweets_sent_count[empresa] = np.unique(empresas_tweets_sent_out[empresa], return_counts=True)
axes[index].pie(empresas_tweets_sent_count[empresa][1], labels=empresas_tweets_sent_count[empresa][0], wedgeprops=dict(width=.5), autopct='%1.f%%')
axes[index].set_title(empresa, fontsize=axes_title_font_size)