from searchtweets import load_credentials, ResultStream, gen_request_parameters, collect_results
search_args = load_credentials(filename="search_tweets_creds.yml",
yaml_key="search_tweets_api",
env_overwrite=False)
empresas = ["Telecentro", "MovistarArg", "ClaroArgentina", "PersonalAr"]
empresas_tweets = dict()
for empresa in empresas:
query = gen_request_parameters(empresa, results_per_call=100, granularity=None)
tweets = collect_results(query,
max_tweets=100,
result_stream_args=search_args)
empresas_tweets[empresa] = tweets[0]['data']Natural Language Processing or NLP is the field of study on computational analysis of human language. This area of knowledge includes a very wide variety of techniques and applications. One of them, within the field of language analysis and comprehension, is Sentiment Analysis, an application that allows a text to be classified according to its positive, negative or neutral charge or polarity.
In this post, with a few lines of python code we’ll do the following tasks:
- Connect to the Twitter API
- Download the latest tweets that mention certain ICT companies
- Use a pre-trained machine learning model to perform sentiment analysis of these tweets
- Visualize the results
The pre-trained model that we are going to use is RoBERTuito, a model trained with 500 million tweets in Spanish. The authors of the paper/model made it available through the platform HuggingFace and the library pysentimento to facilitate NLP research and applications in Spanish.
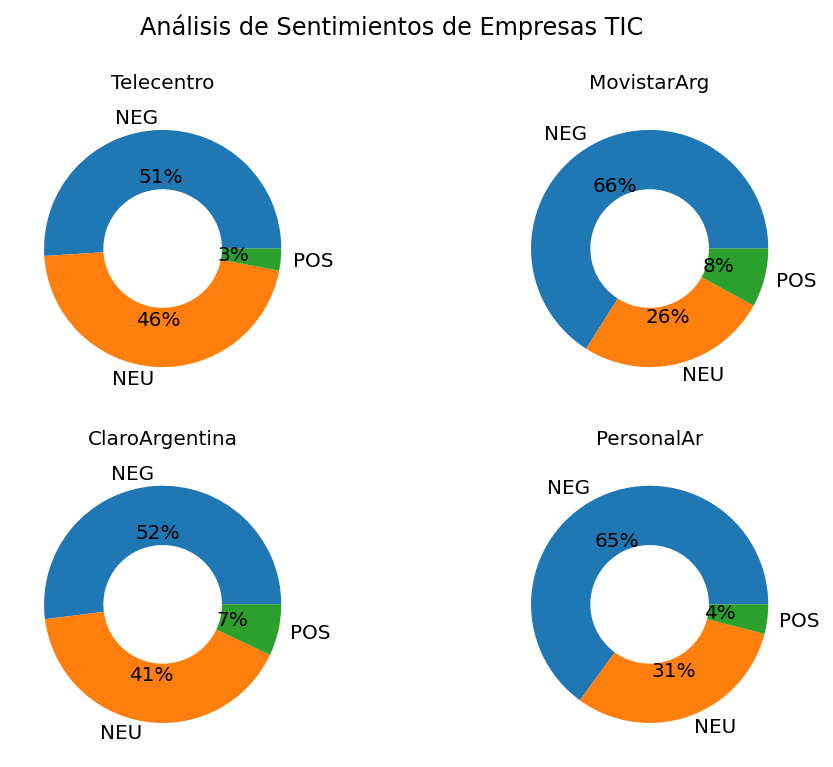
Clarification 1: It is natural and expected that mentions of ICT companies in social media have a negative sentiment, since it is one of the channels for submitting complaints and, as it is a paid service, it is unusual to post a positive comment in case there are no problems with the service.
Clarification 2: to access the tweets, it is necessary to first apply for authentication credentials at Twitter for Developers. Once you have the credentials you should save them in a file called search_tweets_creds.yml with the following structure:
search_tweets_api:
bearer_token: MY_BEARER_TOKEN
endpoint: https://api.twitter.com/2/tweets/search/recentTo obtain the tweets I will use the searchtweets-v2 library, a Python Client for the Twitter API Version 2.
Use the following code for authentication and to obtain the last 100 tweets that mention each of the companies of interest:
Pre-process tweets, apply sentiment analysis and extract the category for each of the tweets and companies:
from pysentimiento import create_analyzer
analyzer = create_analyzer(task="sentiment", lang="es", model_name="pysentimiento/robertuito-sentiment-analysis")
empresas_tweets_sent = dict()
empresas_tweets_sent_out = dict()
for empresa in empresas:
empresas_tweets_sent[empresa] = [analyzer.predict(tuit) for tuit in empresas_tweets_proc[empresa]]
empresas_tweets_sent_out[empresa] = [tuit.output for tuit in empresas_tweets_sent[empresa]]Visualize the results:
import numpy as np
import matplotlib.pyplot as plt
empresas_tweets_sent_count = dict()
fig, axes = plt.subplots(2, 2, figsize=(8, 6),dpi=144)
plt.suptitle("Análisis de Sentimientos de Empresas TIC")
array_index = [(0,0), (0,1), (1,0), (1,1)]
axes_title_font_size = 10
for empresa, index in zip(empresas, array_index):
empresas_tweets_sent_count[empresa] = np.unique(empresas_tweets_sent_out[empresa], return_counts=True)
axes[index].pie(empresas_tweets_sent_count[empresa][1], labels=empresas_tweets_sent_count[empresa][0], wedgeprops=dict(width=.5), autopct='%1.f%%')
axes[index].set_title(empresa, fontsize=axes_title_font_size)